

AI Art Work - DALL·E
Experimenting with generative AI

Taking a quick detour this week from the lithium supply chain and blockchain use cases to generative AI.
I was asked about how to use DALL·E for transforming a sketch into a detailed graphic based on a specific style.
I didn’t know how to do this, but why let that slow me down?
First Try: Generating Variations of an Image
To test out DALL·E’s features, I started with this sketch from my friend Hilary:1
I uploaded this image to DALL·E and generated variations:
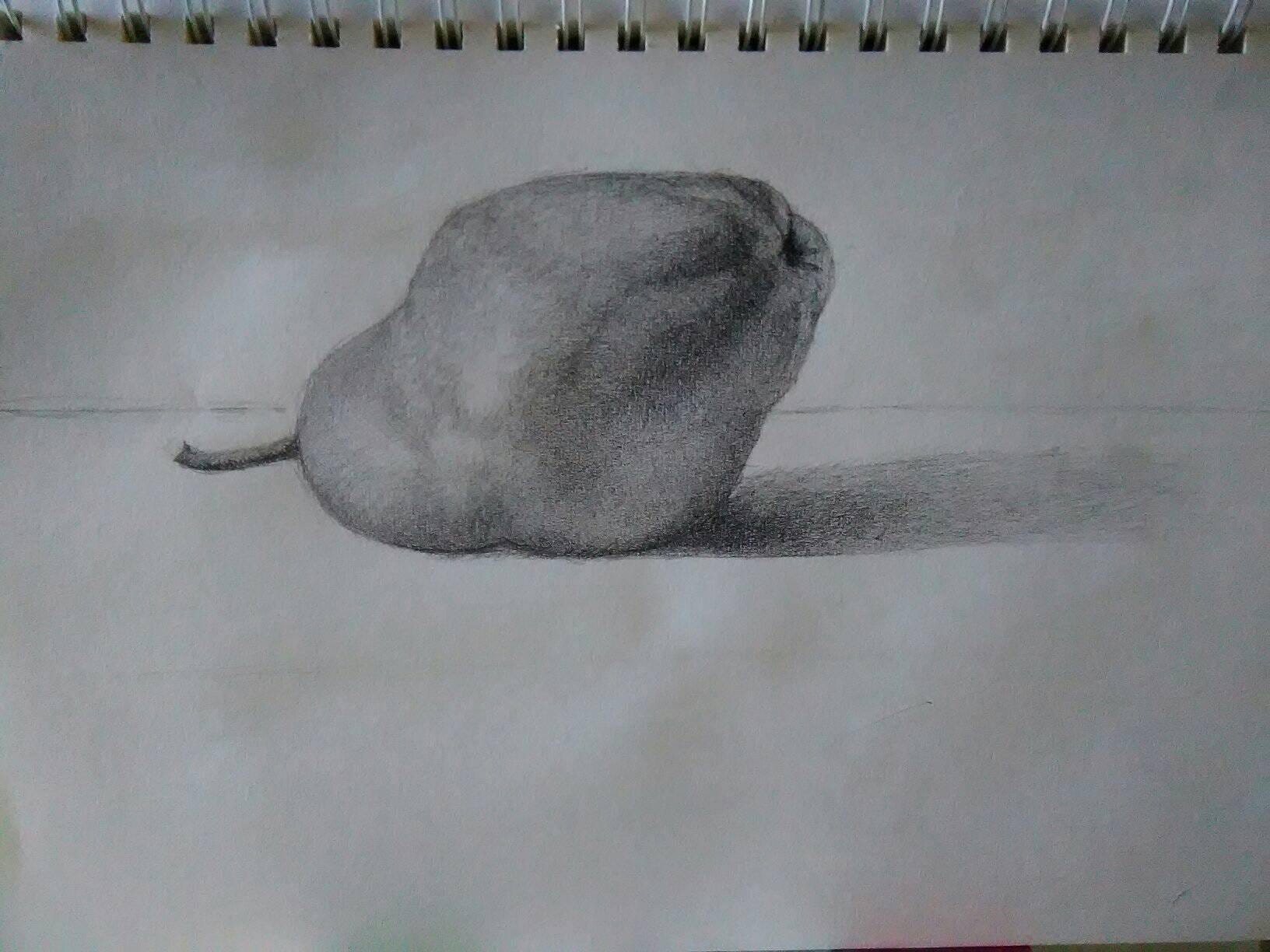
Here are the images produced:



This is good - all of the generated images do look like the original, without being copies.
However, all of the images are in the same style as the original. What if we want something different?
Second Try: Text Prompt Based on Image
My goal wasn’t to generate a series of images that are stylisticly similar to the orignal. My goal is to take an image of a sketch and use generative AI to transform it into a 3D graphic.
I looked for a way to generate an image that is a combination of seed image plus text description in DALL·E, but could not find any.
So, I had a idea. What if I crafted a text prompt that describes my sketch?
artists sketch of a pear



Not bad! The third image is close to the original sketch. Note that I am not using the sketch as input, just as inspiration to craft a text prompt.
Now, I add +”, 3d render” to my original:
artists sketch of a pear, 3d render



Interesting! I like these images. They are all wildly different from each other. My options would be to pick one and generate more variations of it, or craft a more specific addition to my original prompt.
While I like the images produced, I’m still not happy. This doesn’t feel like a very controlled or deterministic process. I want something better.
Third Try: Image to Text?
My next brainstorm to think about how the diffusion algorithm works.
The generation process works to create an image that “fits” the text prompt that is given. This is the normal use case for DALL·E.
But what about the cases of image variation, or scene extension?
In these cases, it seems as if the algorithm must be analyzing the image to create an internal representation, then generating to match.
Great! All we need is to tap into that feature of the algorithm.
Problem: There’s nothing in the DALL·E user interface that provides image-to-text analysis.
What Do You Mean, There’s No API?
Potential solution: maybe DALL·E’s API exposes that functionality?
Nope. OpenAI hasn’t released an API for DALL·E yet.
Checkmate, human.
Looking For Other Options
DALL·E isn’t the only image generation AI out there. Next time, I’ll work through the same problem using Stable Diffusion.
Go to Hilary White Sacred Art to support her work.
Why yes, Zach, I'm happy to give you permission to use my work in a blog post...
<...Ahem...>